Intelligent Search Engine For Pdf Files With Metadata
FEATURES
- Using Envirya Project’s proprietary Artificial Intelligence based Intelligent Search Engine, users can search and obtain accurate results from various scanned PDF files (having extracted data/metadata). This shall aid authorities in CLIENT to efficiently search and browse data, primarily to search through keywords pertaining to Queries and it’s replies utilizing Document Engine Optimization and other proprietary technologies and make them accessible by viewing the original PDFs and also in a single editable MS Word file in an aggregated manner so that CLIENT authorities can take informed decisions and create reports correctly and swiftly.
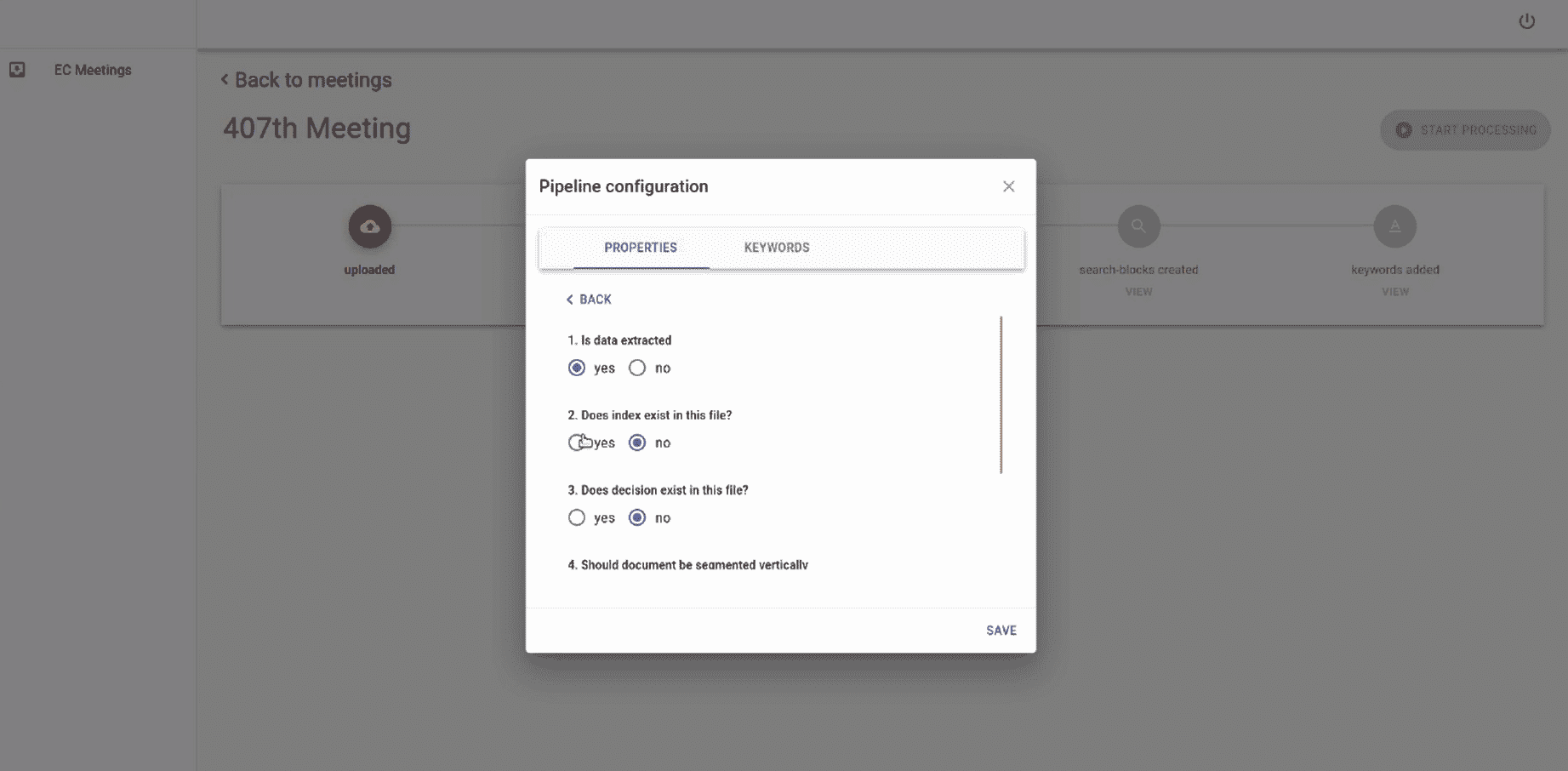
- Document Engine Optimization accessed through customizable settings, shall provide faster and more efficient search through usage of proprietary technologies. Proprietary classification algorithm shall classify the data given out in various forms through another proprietary algorithm.
- Multiple users of the client will have access to the Intelligent Search Engine for PDF files with metadata.
- The query data shall get linked to its respective linksthrough our proprietary algorithm (based on data provided by CLIENT).
- Type of data required shall be accessed through pre-defined search parameters that can be selected through customizable settings.
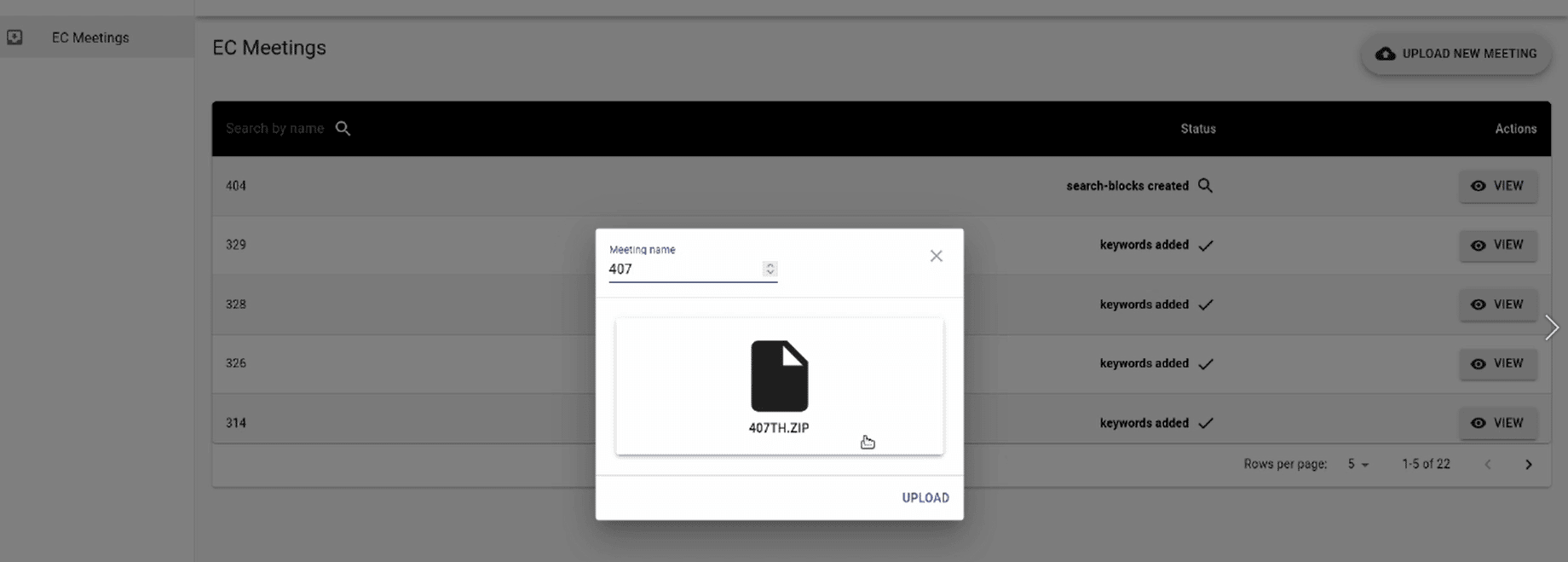
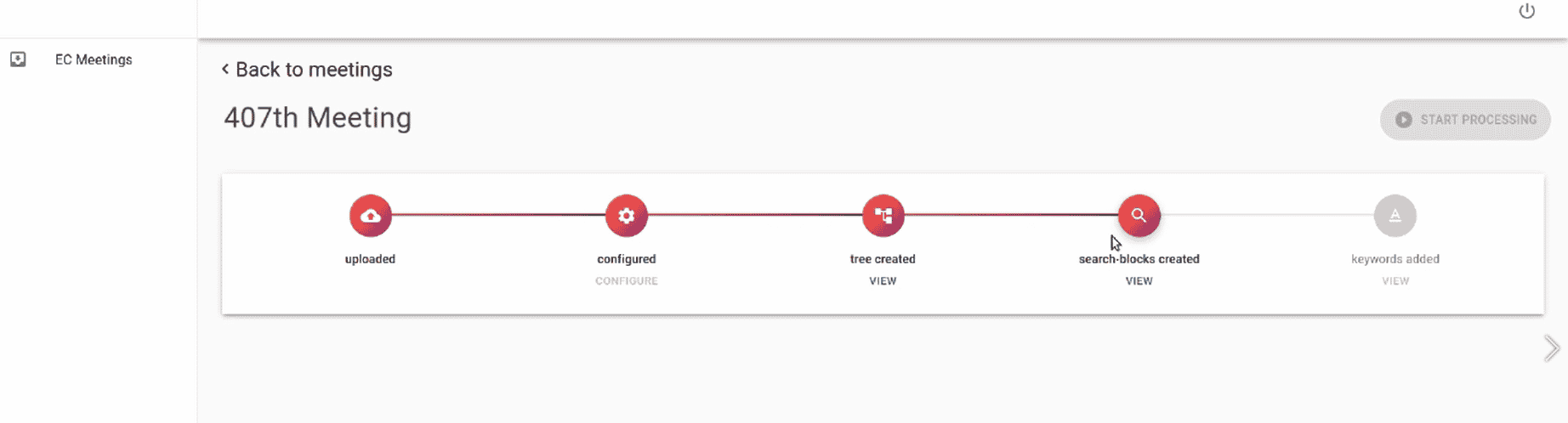
- While uploading new datasets on the platform through the admin portal, the proprietary algorithms shallassociate and classify the data and link them.
- Users will have the ability to perform the following actions at the landing page of the Search engine:
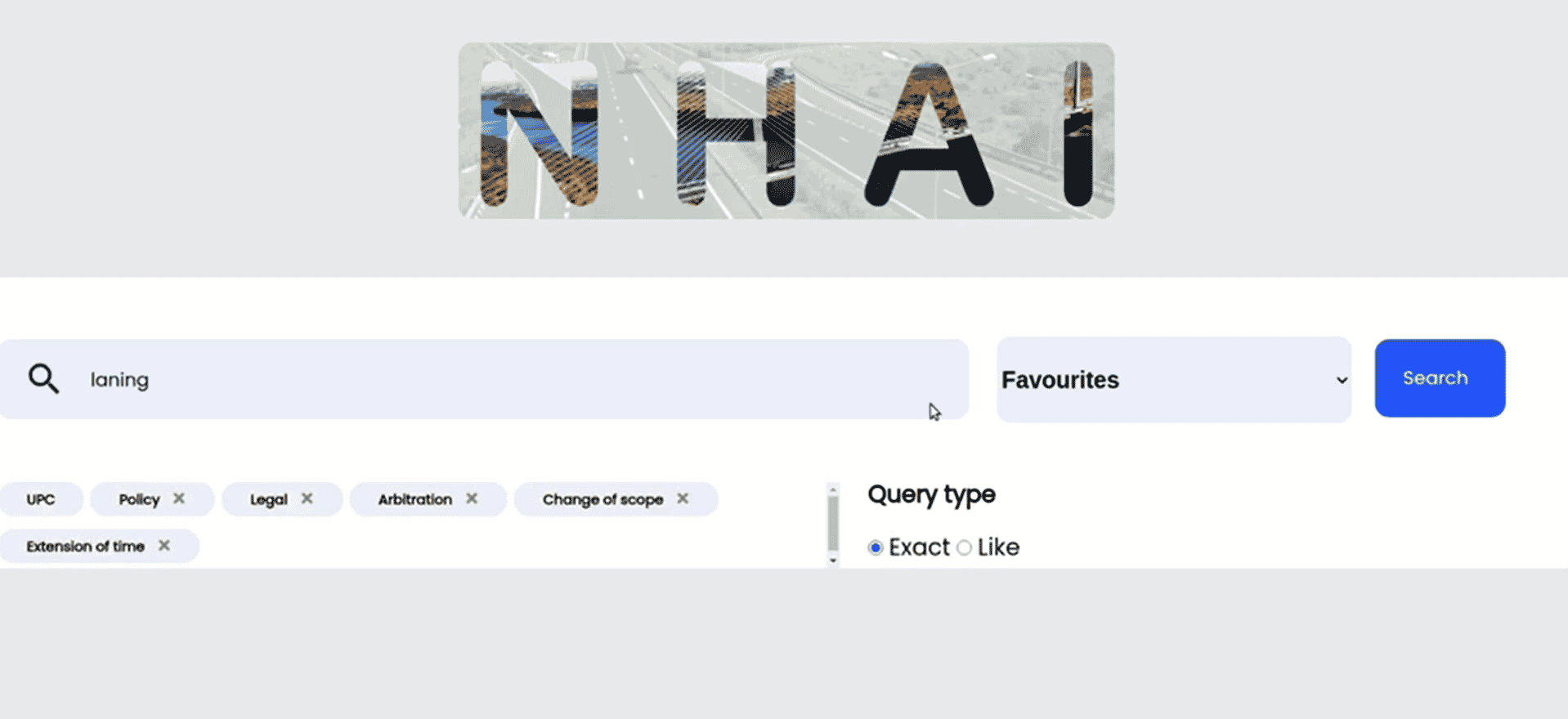
a. Input search keywords in the search bar.
b. Choose filters from a collection (as provided by CLIENT).
c. Select the type of “Search algorithm”, i.e., Exact or Like.
d. Upload an excel file to search for a query through subject extracted from associated documents. The Search Workflow is as under:
b. Choose filters from a collection (as provided by CLIENT).
c. Select the type of “Search algorithm”, i.e., Exact or Like.
d. Upload an excel file to search for a query through subject extracted from associated documents. The Search Workflow is as under:
- Prompt user for the upload of excel file containing subject (linked to the documents provided by client).
- Show the excel view of the uploaded excel file. Upon clicking on the same (linked to data provided by the client), shall be populated in the search bar and thereafter lead to a search result.
- Aggregated search result in MS-Word format can be downloaded, and the original PDF from where the search was found can also be accessed.
e. Perform specific search or global search.
f. Auto categorization based on documents.
f. Auto categorization based on documents.
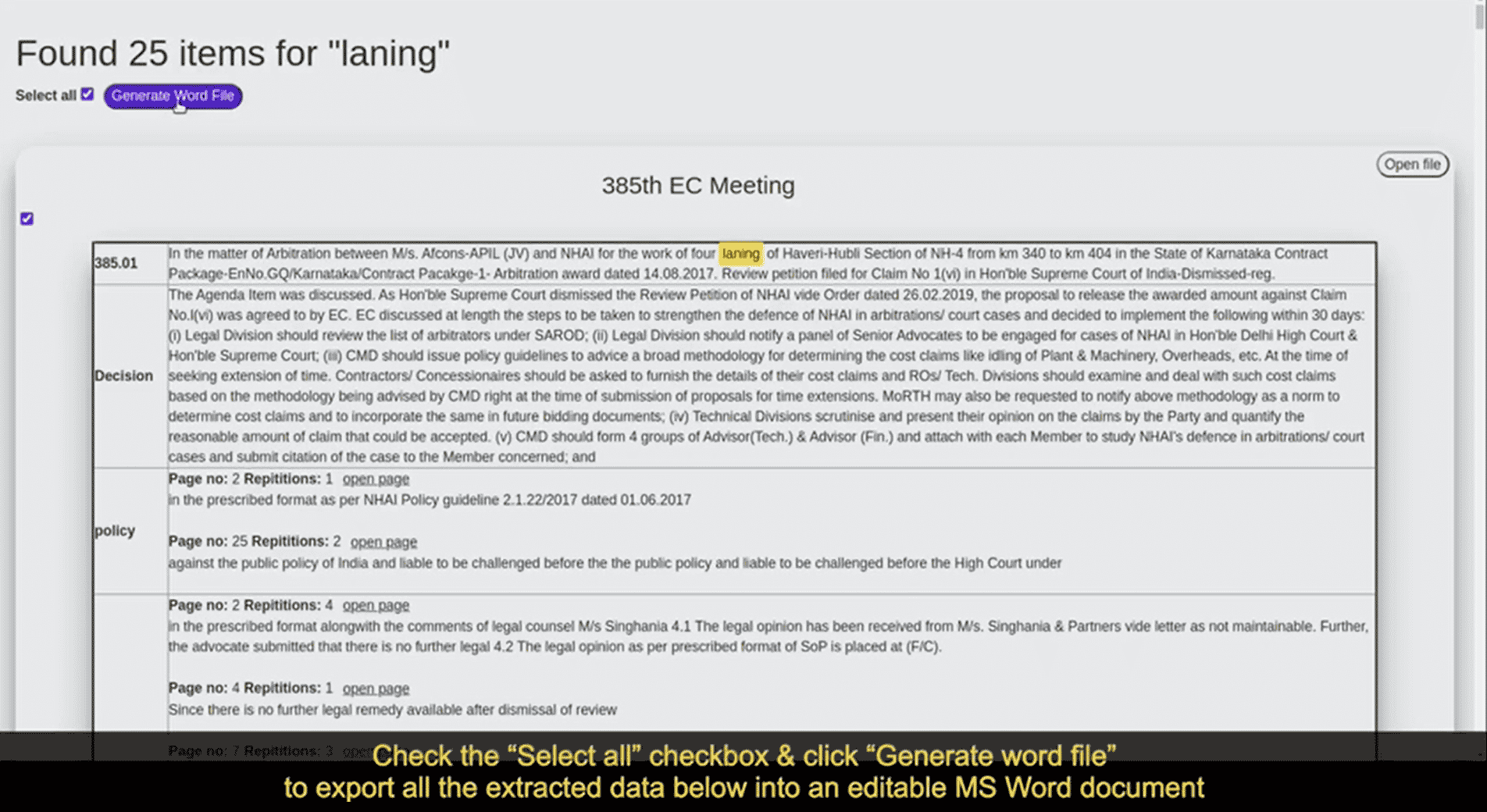
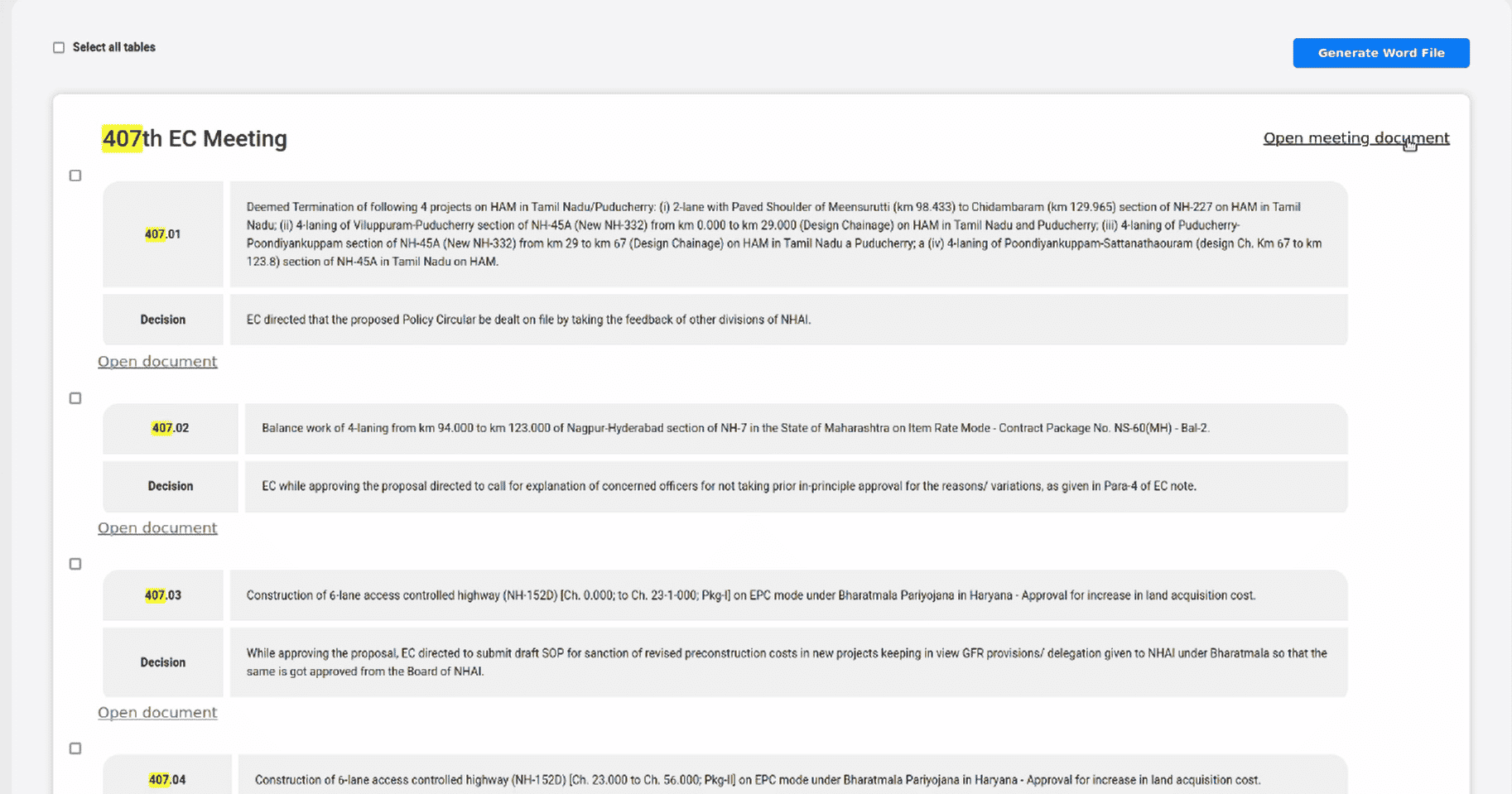
- 8. A specific search can be performed by inputting the keyword in the search bar. This will lead to aggregation of data having the particular keyword being searched(already classified by proprietary algorithm for pre-defined work types, wherein the user can select the type of search algorithm to run the query from: Like and Exact. This will give the appropriateaggregated resultsas desired by the client.The displayed results can be aggregated as a single editable MS Word file, which can be downloaded.
- 9. A global search can be performed by inputting “*”.This will lead to aggregation of data of all documents (already classified by proprietary algorithm for pre-defined work types, wherein the user can select the type of search algorithm to run the query from: Like and Exact. If the query is exact then only those documents will be displayed which are associated with the same pre-defined keywords which are selected under the search bar checkbox, else if the query is Like, then it will display anyone or more of the pre-defined keywords which are selected under the search bar checkbox). This will give the appropriate aggregated results in the form as desired by client. The displayed results can be aggregated as a single editable MS Word file, which can be downloaded.
- 10. The following is an example as illustrated in the following Figures 1 and 2 :-
a. Specific Search
- The user keys in a search “Traffic signage plan”
- Check Boxes in the form of pre-defined Keywords:The user can also select or add searches by selecting check boxes from the various pre-defined keywords(provided by CLIENT at the time of uploading datasets).
- Selection of the type of “Search algorithm”, i.e., Exact or Like.
b. Global Search
- The user keys in a search “*”
- Check Boxes in the form of pre-defined Keywords:The user can also select or add searches by selecting check boxes from the various pre-defined keywords(provided by CLIENT at the time of uploading datasets).
- Selection of the type of “Search algorithm”, i.e., Exact or Like.
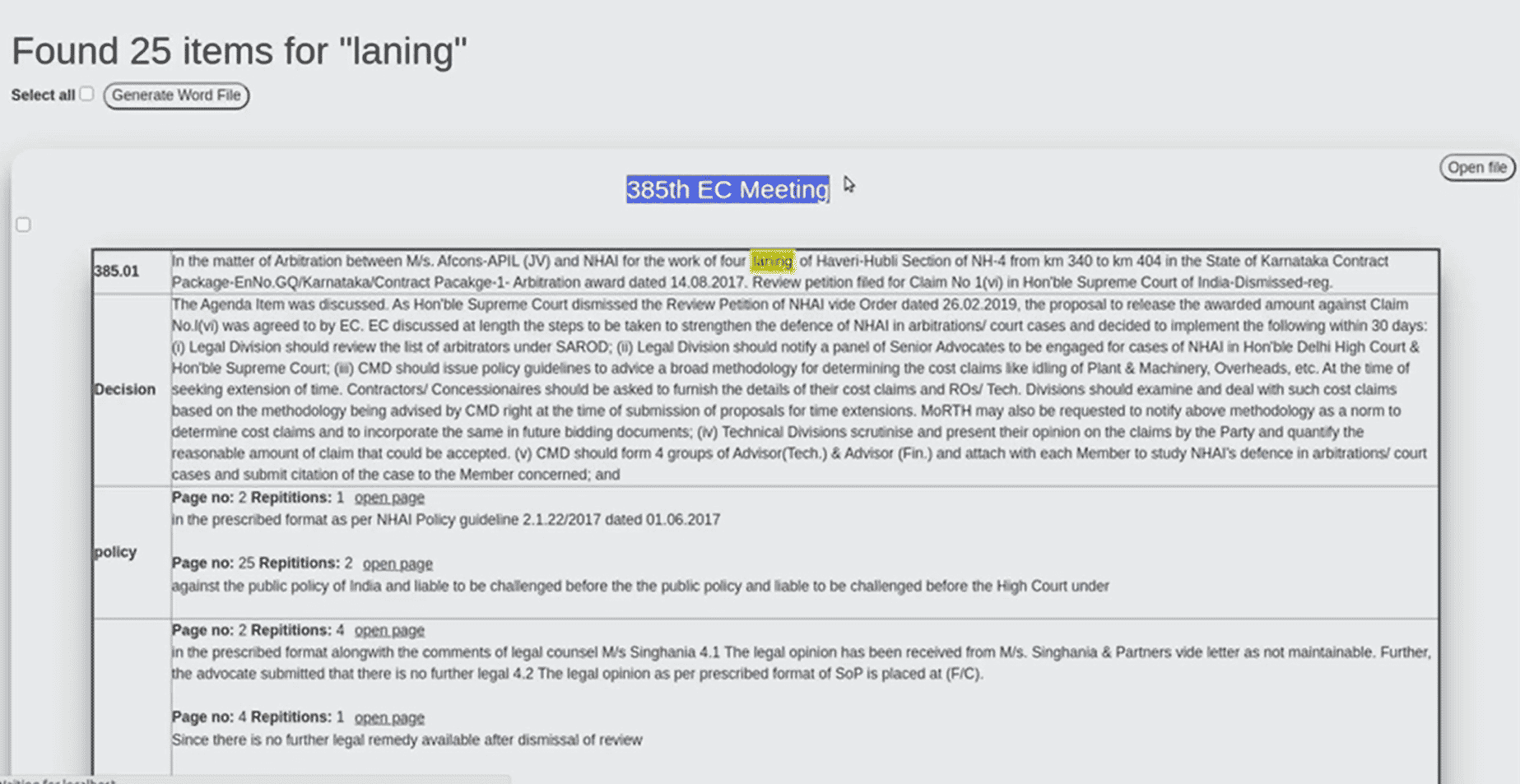
11. The engine displays the following within a matter of seconds:
- Results from where data is extracted: The search engine results for which the search query is valid. The searched keyword gets highlighted in the displayed results.
- View original PDF Files: The user can open the original scanned PDF file where the searched query resides.
- Aggregated data from list of documents: This will be one editable MS Word document which contains aggregated data pulled from all the list of documents to be viewed in one file.
NOTE :
- All the pre-defined work types shall be provided by the CLIENT on which the classification algorithm shall be developed.
- The platform shall be installed on CLIENT servers. No data will travel outside the designated cloud as specified by CLIENT.